Tutorial¶
This Jupyter Notebook provides a tutorial for the features of plumpy.
To use, create an environment with:
$ conda create -n plumpy-tutorial plumpy>=0.18 jupyterlab
$ conda activate plumpy-tutorial
and open jupyterlab in the notebook folder:
$ jupyter lab
import asyncio
from pprint import pprint
import time
import kiwipy
import plumpy
# this is required because jupyter is already running an event loop
plumpy.set_event_loop_policy()
Introduction¶
Plumpy is a library used to create and control long-running workflows.
The library consists of a number of key components, that we will shall cover:
- The
Process To run a user defined action, with well defined inputs and outputs.
- The
WorkChain A subclass of
Processthat allows for running a process as a set of discrete steps (also known as instructions), with the ability to save the state of the process after each instruction has completed.- The process
Controller(principally theRemoteProcessThreadController) To control the process or workchain throughout its lifetime.
Processes¶
The Process is the minimal component of the plumpy workflow.
It utilises the concept of a finite state machine to run a user defined action, transitioning between a set of states:
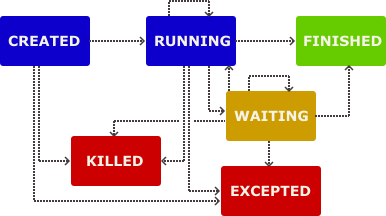
Process state transitions¶
The simplest process, implements a run method and can be executed with the execute method:
class SimpleProcess(plumpy.Process):
def run(self):
print(self.state.name)
process = SimpleProcess()
print(process.state.name)
process.execute()
print(process.state.name)
print("Success", process.is_successful)
print("Result", process.result())
CREATED
RUNNING
FINISHED
Success True
Result None
Defining inputs and outputs¶
To integrate the process into a more complex workflow, you can define an input and output ProcessSpec.
Important
define is a class method and should always call the super method.
The process specification creates Port, which can have help strings, defaults and validators, and can be nested in PortNamespace.
class SpecProcess(plumpy.Process):
@classmethod
def define(cls, spec: plumpy.ProcessSpec):
super().define(spec)
spec.input('input1', valid_type=str, help='A help string')
spec.output('output1')
spec.input_namespace('input2')
spec.input('input2.input2a')
spec.input('input2.input2b', default='default')
spec.output_namespace('output2')
spec.output('output2.output2a')
spec.output('output2.output2b')
def run(self):
self.out('output1', self.inputs.input1)
self.out('output2.output2a', self.inputs.input2.input2a)
self.out('output2.output2b', self.inputs.input2.input2b)
pprint(SpecProcess.spec().get_description())
process = SpecProcess(inputs={
'input1': 'my input',
'input2': {'input2a': 'other input'}
})
process.execute()
process.outputs
{'inputs': {'_attrs': {'default': (),
'dynamic': False,
'help': None,
'required': 'True',
'valid_type': 'None'},
'input1': {'help': 'A help string',
'name': 'input1',
'required': 'True',
'valid_type': "<class 'str'>"},
'input2': {'_attrs': {'default': (),
'dynamic': False,
'help': None,
'required': 'True',
'valid_type': 'None'},
'input2a': {'name': 'input2a', 'required': 'True'},
'input2b': {'default': 'default',
'name': 'input2b',
'required': 'False'}}},
'outputs': {'_attrs': {'default': (),
'dynamic': False,
'help': None,
'required': 'True',
'valid_type': 'None'},
'output1': {'name': 'output1', 'required': 'True'},
'output2': {'_attrs': {'default': (),
'dynamic': False,
'help': None,
'required': 'True',
'valid_type': 'None'},
'output2a': {'name': 'output2a', 'required': 'True'},
'output2b': {'name': 'output2b', 'required': 'True'}}}}
{'output1': 'my input',
'output2': {'output2a': 'other input', 'output2b': 'default'}}
Commands and actions¶
The run method can also return a Command, to tell the process what action to perform next.
By default the command is plumpy.Stop(result=None, successful=True), but you can also, for example, return a Continue command with another function to run:
class ContinueProcess(plumpy.Process):
def run(self):
print("running")
return plumpy.Continue(self.continue_fn)
def continue_fn(self):
print("continuing")
# message is stored in the process status
return plumpy.Kill("I was killed")
process = ContinueProcess()
try:
process.execute()
except plumpy.KilledError as error:
pass
print(process.state)
print(process.status)
process.is_successful
running
continuing
ProcessState.KILLED
I was killed
False
Listeners¶
By defining and adding a ProcessListener to a process, we can add functions which are triggered when the process enters a particular state.
class WaitListener(plumpy.ProcessListener):
def on_process_running(self, process):
print(process.state.name)
def on_process_waiting(self, process):
print(process.state.name)
process.resume()
class WaitProcess(plumpy.Process):
def run(self):
return plumpy.Wait(self.resume_fn)
def resume_fn(self):
return plumpy.Stop(None, True)
process = WaitProcess()
print(process.state.name)
listener = WaitListener()
process.add_process_listener(listener)
process.execute()
print(process.state.name)
CREATED
RUNNING
WAITING
RUNNING
FINISHED
Asynchronicity¶
Processes run asynchronously on the asyncio event loop,
with step_until_terminated the higher level async function inside of the execute method that drives the execution.
Note that each process will always run its steps synchronously and that Continue commands will not relinquish the control of the event loop.
In the following section on WorkChains we will see how to run steps that do relinquish the event loop control, allowing for multiple processes to run asynchronously.
async def async_fn():
print("async_fn start")
await asyncio.sleep(.01)
print("async_fn end")
class NamedProcess(plumpy.Process):
@classmethod
def define(cls, spec: plumpy.ProcessSpec):
super().define(spec)
spec.input('name')
def run(self):
print(self.inputs.name, "run")
return plumpy.Continue(self.continue_fn)
def continue_fn(self):
print(self.inputs.name, "continued")
process1 = NamedProcess({"name": "process1"})
process2 = NamedProcess({"name": "process2"})
async def execute():
await asyncio.gather(
async_fn(),
process1.step_until_terminated(),
process2.step_until_terminated()
)
plumpy.get_event_loop().run_until_complete(execute())
async_fn start
process1 run
process1 continued
process2 run
process2 continued
async_fn end
Pausing and playing¶
Pausing a process will create an action to await a pause Future before the start of the next step, i.e. it will still finish the current step before awaiting.
When awaiting the pause Future the event loop control is relinquished, and so other processes are free to start.
Note
Pausing a process does not change its state and is different to the concept of waiting.
The pause Future can be marked as done, and thus the process continued, via the use of the play method.
If the play is called before then end of the step during which the process was paused, it will cancel the pause action.
Below is a toy example, but this concept becomes more useful when using a Controller, as discussed later.
class SimpleProcess(plumpy.Process):
def run(self):
print(self.get_name())
class PauseProcess(plumpy.Process):
def run(self):
print(f"{self.get_name()}: pausing")
self.pause()
print(f"{self.get_name()}: continue step")
return plumpy.Continue(self.next_step)
def next_step(self):
print(f"{self.get_name()}: next step")
pause_proc = PauseProcess()
simple_proc = SimpleProcess()
async def play(proc):
while True:
if proc.paused:
print(f"{proc.get_name()}: playing (state={proc.state.name})")
proc.play()
break
async def execute():
return await asyncio.gather(
pause_proc.step_until_terminated(),
simple_proc.step_until_terminated(),
play(pause_proc),
)
outputs = plumpy.get_event_loop().run_until_complete(execute())
PauseProcess: pausing
PauseProcess: continue step
SimpleProcess
PauseProcess: playing (state=RUNNING)
PauseProcess: next step
WorkChains¶
Introduction¶
The WorkChain allows for improved logic, when it comes to running a process as a set of discrete steps (also known as instructions).
The set of steps are defined in the outline(), which defines a succinct summary of the logical steps that the workchain will perform.
class SimpleWorkChain(plumpy.WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.outline(
cls.step1,
cls.step2,
)
def step1(self):
print('step1')
def step2(self):
print('step2')
workchain = SimpleWorkChain()
output = workchain.execute()
step1
step2
Conditionals¶
The outline can contain more than just a list of steps.
It allows for “conditionals” which should return a truthy value to indicate if the nested steps should be run.
For example, using the if_ conditional.
class IfWorkChain(plumpy.WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.input('run', valid_type=bool)
spec.outline(
plumpy.if_(cls.if_step)(
cls.conditional_step
)
)
def if_step(self):
print(' if')
return self.inputs.run
def conditional_step(self):
print(' conditional')
workchain = IfWorkChain({"run": False})
print('execute False')
output = workchain.execute()
workchain = IfWorkChain({"run": True})
print('execute True')
output = workchain.execute()
execute False
if
execute True
if
conditional
The context and while conditional¶
The while_ conditional allows steps to be run multiple times.
To achieve this we need to define and iterate an internal variable.
It is important that these variables are saved on the WorkChain.ctx attribute (an AttributesDict), since this can be persisted in between steps as we will discuss later.
Important
Arbitrary WorkChain instance attributes will not be persisted.
Internal variables should always be saved to self.ctx.
class WhileWorkChain(plumpy.WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.input('steps', valid_type=int, default=3)
spec.outline(
cls.init_step,
plumpy.while_(cls.while_step)(
cls.conditional_step
)
)
def init_step(self):
self.ctx.iterator = 0
def while_step(self):
self.ctx.iterator += 1
return (self.ctx.iterator <= self.inputs.steps)
def conditional_step(self):
print('step', self.ctx.iterator)
workchain = WhileWorkChain()
output = workchain.execute()
step 1
step 2
step 3
Interstep processes and asynchronicity¶
By default, each “non-terminal” step will return a Continue command, to progress to the next step (as a RUNNING state).
In terms of asynchronicity, this means that no step will relinquish control to the asyncio event loop.
By using the to_context method though, we can add “awaitable” objects.
If the step adds any of these objects, then the workchain is transitioned into a WAITING state until the awaitables are complete, at which point the workchain moves on to the next step.
The following example shows how to add an arbitrary asychronous function and a Process as awaitables. You could even add nested WrokChain with their own interstep processes.
async def awaitable_func(msg):
await asyncio.sleep(.01)
print(msg)
return True
class InternalProcess(plumpy.Process):
@classmethod
def define(cls, spec):
super().define(spec)
spec.input('name', valid_type=str, default='process')
spec.output('value')
def run(self):
print(self.inputs.name)
self.out('value', 'value')
class InterstepWorkChain(plumpy.WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.input('name', valid_type=str, default='workchain')
spec.input('process', valid_type=bool, default=False)
spec.input('awaitable', valid_type=bool, default=False)
spec.outline(
cls.step1,
cls.step2,
cls.step3,
)
def step1(self):
print(self.inputs.name, 'step1')
def step2(self):
print(self.inputs.name, 'step2')
time.sleep(.01)
if self.inputs.awaitable:
self.to_context(
awaitable=asyncio.ensure_future(
awaitable_func(f'{self.inputs.name} step2 awaitable'),
loop=self.loop
)
)
if self.inputs.process:
self.to_context(
process=self.launch(
InternalProcess,
inputs={'name': f'{self.inputs.name} step2 process'})
)
def step3(self):
print(self.inputs.name, 'step3')
print(f" ctx={self.ctx}")
Without awaitables, we can see that each workchain runs to completion before the next workchain starts.
wkchain1 = InterstepWorkChain({'name': 'wkchain1'})
wkchain2 = InterstepWorkChain({'name': 'wkchain2'})
async def execute():
return await asyncio.gather(
wkchain1.step_until_terminated(),
wkchain2.step_until_terminated()
)
output = plumpy.get_event_loop().run_until_complete(execute())
wkchain1 step1
wkchain1 step2
wkchain1 step3
ctx=AttributesDict()
wkchain2 step1
wkchain2 step2
wkchain2 step3
ctx=AttributesDict()
By adding an interstep process we see that the workchain, in the WAITING state, relinquishes control of the event loop for other workchains to start.
The outputs of interstep awaitables are saved on on the workchain’s context for later use.
wkchain1 = InterstepWorkChain({'name': 'wkchain1', 'process': True})
wkchain2 = InterstepWorkChain({'name': 'wkchain2', 'process': True})
async def execute():
return await asyncio.gather(
wkchain1.step_until_terminated(),
wkchain2.step_until_terminated()
)
output = plumpy.get_event_loop().run_until_complete(execute())
wkchain1 step1
wkchain1 step2
wkchain2 step1
wkchain2 step2
wkchain1 step2 process
wkchain2 step2 process
wkchain1 step3
ctx=AttributesDict(process={'value': 'value'})
wkchain2 step3
ctx=AttributesDict(process={'value': 'value'})
wkchain1 = InterstepWorkChain({'name': 'wkchain1', 'awaitable': True})
wkchain2 = InterstepWorkChain({'name': 'wkchain2', 'awaitable': True})
async def execute():
return await asyncio.gather(
wkchain1.step_until_terminated(),
wkchain2.step_until_terminated()
)
output = plumpy.get_event_loop().run_until_complete(execute())
wkchain1 step1
wkchain1 step2
wkchain2 step1
wkchain2 step2
wkchain1 step2 awaitable
wkchain2 step2 awaitable
wkchain1 step3
ctx=AttributesDict(awaitable=True)
wkchain2 step3
ctx=AttributesDict(awaitable=True)
Although the steps of individual workchains always progress synchronusly, the order of interleaving of steps from different workchains is non-deterministic.
wkchain1 = InterstepWorkChain({'name': 'wkchain1', 'process': True, 'awaitable': True})
wkchain2 = InterstepWorkChain({'name': 'wkchain2', 'process': True, 'awaitable': True})
async def execute():
return await asyncio.gather(
wkchain1.step_until_terminated(),
wkchain2.step_until_terminated()
)
output = plumpy.get_event_loop().run_until_complete(execute())
wkchain1 step1
wkchain1 step2
wkchain2 step1
wkchain2 step2
wkchain1 step2 process
wkchain2 step2 process
wkchain1 step2 awaitable
wkchain2 step2 awaitable
wkchain1 step3
ctx=AttributesDict(awaitable=True, process={'value': 'value'})
wkchain2 step3
ctx=AttributesDict(awaitable=True, process={'value': 'value'})
Persistence¶
A process can be saved as a checkpoint by a Persister implementation,
recording enough information to fully recreate the current instance state.
Out-of-the-box implemented persisters are the InMemoryPersister and PicklePersister.
Below is a toy implementation, but they are primarily used as part of the Controller functionality described later.
persister = plumpy.InMemoryPersister()
class PersistWorkChain(plumpy.WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.outline(
cls.init_step,
cls.step2,
cls.step3,
)
def __repr__(self):
return f"PersistWorkChain(ctx={self.ctx})"
def init_step(self):
self.ctx.step = 1
persister.save_checkpoint(self, 'init')
def step2(self):
self.ctx.step += 1
persister.save_checkpoint(self, 'step2')
def step3(self):
self.ctx.step += 1
persister.save_checkpoint(self, 'step3')
workchain = PersistWorkChain()
workchain.execute()
workchain
PersistWorkChain(ctx=AttributesDict(step=3))
The persister now contains three checkpoints:
persister.get_checkpoints()
[PersistedCheckpoint(pid=UUID('0175da80-5715-4067-a9db-1a7a7ee01eec'), tag='init'),
PersistedCheckpoint(pid=UUID('0175da80-5715-4067-a9db-1a7a7ee01eec'), tag='step2'),
PersistedCheckpoint(pid=UUID('0175da80-5715-4067-a9db-1a7a7ee01eec'), tag='step3')]
Checkpoints can be accessed via the processes PID and the given checkpoint tag. This returns a Bundle, which can be used to recreate the workchain instance state at the point of the checkpoint:
workchain_checkpoint = persister.load_checkpoint(workchain.pid, 'step2').unbundle()
workchain_checkpoint
PersistWorkChain(ctx=AttributesDict(step=2))
Communicators and Controllers¶
kiwipy communicators can send messages to subscribers, to launch or control processes.
Messages take one of three forms:
- Tasks are one to many messages.
This means that you sent out a task to a queue and there can be zero or more subscribers attached one of which will process the task when it is ready.
The result of the task can optionally be delivered to the sender.
- A Remote Procedure Call (RPC) is one-to-one.
This is used when you want to call a particular remote function/method and (usually) expect an immediate response.
For example imagine asking a remote process to pause itself.
Here you would make a RPC and wait to get confirmation that it has, indeed, paused.
- Broadcasters send messages to to zero or more consumers.
These are fire and forget calls that broadcast a message to anyone who is listening.
Consumers may optionally apply a filter to only receive messages that match some criteria.
As a simple example, a process can take a communicator on initiation. On process creation, this will add the process to the communicator as an RPC and broadcast subscriber, the communicator can then send RPC messages via a processes PID (as a string) or broadcast to all subscribed processes. Four message types are available:
STATUS(RPC only)KILLPAUSEPLAY
Important
On process termination/close it will remove the process subscriptions to the communicator.
communicator = kiwipy.LocalCommunicator()
class SimpleProcess(plumpy.Process):
pass
process = SimpleProcess(communicator=communicator)
pprint(communicator.rpc_send(str(process.pid), plumpy.STATUS_MSG).result())
{'ctime': 1649438757.413114,
'paused': False,
'process_string': '<SimpleProcess> (ProcessState.CREATED)',
'state': 'ProcessState.CREATED'}
A ProcessLauncher can be subscribed to a communicator, for process launch and continue tasks.
Process controllers can then wrap a communicator, to provide an improved interface.
class ControlledWorkChain(plumpy.WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.input('steps', valid_type=int, default=10)
spec.output('result', valid_type=int)
spec.outline(
cls.init_step,
plumpy.while_(cls.while_step)(cls.loop_step),
cls.final_step
)
def init_step(self):
self.ctx.iterator = 0
def while_step(self):
return (self.ctx.iterator <= self.inputs.steps)
def loop_step(self):
self.ctx.iterator += 1
def final_step(self):
self.out('result', self.ctx.iterator)
loop_communicator = plumpy.wrap_communicator(kiwipy.LocalCommunicator())
loop_communicator.add_task_subscriber(plumpy.ProcessLauncher())
controller = plumpy.RemoteProcessController(loop_communicator)
wkchain = ControlledWorkChain(communicator=loop_communicator)
async def run_wait():
return await controller.launch_process(ControlledWorkChain)
async def run_nowait():
return await controller.launch_process(ControlledWorkChain, nowait=True)
print(plumpy.get_event_loop().run_until_complete(run_wait()))
print(plumpy.get_event_loop().run_until_complete(run_nowait()))
{'result': 11}
3f43527d-4ca6-403b-935b-b6fb94624bc0
more to come…